이번 글에서는 시리즈 vs 숫자, 시리즈 vs 시리즈 연산을 정리하고자 한다.
판다스 객체의 산술연산은 내부적으로 3단계 프로세스를 거친다.
1. 행/열 인덱스를 기준으로 모든 원소를 정렬한다.
2. 동일한 위치에 있는 원소끼리 일대일로 대응시킨다.
3. 일대일 대응이 되는 원소끼리 연산을 처리한다. (대응되는 원소가 없으면 NaN으로 처리한다)
시리즈 vs 숫자
시리즈와 숫자 연산: Series 객체 + 연산자(+, -, *, /) + 숫자
시리즈 객체에 어떤 숫자를 더하면 시리즈의 개별 원소에 각각 숫자를 더하고 계산한 결과를 시리즈 객체로 반환한다.
덧셈, 뺄셈, 곱셈, 나눗셈 모두 가능하며 아래 예제는 시리즈 객체의 각 원소를 100으로 나누는 과정이다.
import pandas as pd
student = pd.Series({'국어': 100, '영어': 80, '수학': 90})
print(student)
print('\n')
# 학생의 과목별 점수를 100으로 나누기
percentage = student / 100
print(percentage)
print('\n')
print(type(percentage))
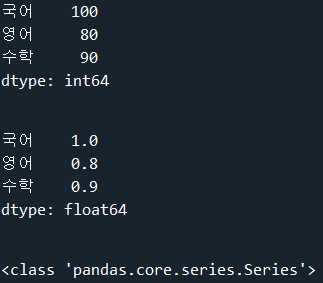
각 과목의 점수를 100으로 나눈 값이 percentage에 들어간 것을 알 수 있다.
시리즈 vs 시리즈
시리즈와 시리즈 연산: Series1 + 연산자(+, -, *, /) + Series2
시리즈의 모든 인덱스에 대하여 같은 인덱스를 가진 원소끼리 계산하고 연산 결과를 매칭하여 새 시리즈를 반환한다.
다음의 예제는 두 시리즈 간의 사칙연산을 먼저 처리한다. 그리고 연산의 결과로 반환된 4개의 시리즈 객체를 DataFrame() 메소드를 이용하여 하나의 데이터 프레임으로 합치는 과정을 보여준다.
import pandas as pd
student1 = pd.Series({'국어': 100, '영어': 80, '수학': 90})
student2 = pd.Series({'수학': 80, '국어': 90, '영어': 80})
addition = student1 + student2
subtraction = student1 - student2
multiplication = student1 * student2
division = student1 / student2
# 사칙연산 결과를 데이터프레임으로 합치기(시리즈 -> 데이터프레임)
result = pd.DataFrame([addition, subtraction, multiplication, division],
index= ['덧셈', '뺄셈', '곱셈', '나눗셈'])
print(result)

각 연산의 결과를 데이터 프레임으로 합친 모습을 볼 수 있다. 위 예제에서 인덱스로 주어진 과목명의 순서가 다르지만, 판다스는 같은 과목명(인덱스)을 찾아 정렬한 후 같은 과목명(인덱스)의 점수 데이터 값끼리 덧셈을 한다. 덧셈의 결과를 과목명(인덱스)에 매칭 시키고 새로운 시리즈 객체를 반환한다.
Spyder에서 코드를 실행한 결과 출력 형태가 정렬이 되어있지 않다는 느낌이 들었다. 그래서 값을 복사해서 메모장에 붙여넣기를 하니 아래 그림처럼 가운데 정렬을 해서 값이 들어간 형태로 보였다. 출력과 관련해서도 공부를 하고 포스팅을 하도록 해야겠다.

만약 두 시리즈의 원소 개수가 다르거나, 시리즈의 크기가 같더라고 인덱스 값이 다른 경우는 어떻게 할까? 이처럼 어느 한쪽에만 인덱스가 존재하는 경우에는 정상적으로 연산을 처리할 수 없다. 판다스는 유효한 값이 존재하지 않는다는 의미를 갖는 NaN으로 처리한다.
동일한 인덱스가 양쪽에 모두 존재하여 서로 대응되더라도 어느 한 쪽의 데이터 값이 NaN인 경우가 있다. 이때도 연산의 대상인 데이터가 존재하지 않는다고 판단하여 연산 결과는 NaN이 된다.
NaN으로 출력되는 상황을 피하기 위해서 연산 메소드에 fill_value 옵션을 적용할 수 있다. NaN을 대신한 값을 설정하면 된다.
import pandas as pd
import numpy as np
student1 = pd.Series({'국어': np.nan, '영어': 80, '수학': 90})
student2 = pd.Series({'수학': 80, '국어': 90})
sr_add = student1.add(student2, fill_value = 0)
sr_sub = student1.sub(student2, fill_value = 0)
sr_mul = student1.mul(student2, fill_value = 0)
sr_div = student1.div(student2, fill_value = 0)
# 사칙연산 결과를 데이터프레임으로 합치기(시리즈 -> 데이터프레임)
result = pd.DataFrame([sr_add, sr_sub, sr_mul, sr_div],
index= ['덧셈', '뺄셈', '곱셈', '나눗셈'])
print(result)

NaN 대신 0값이 들어간 것을 알 수 있다.
'Data Engineering > 데이터 분석' 카테고리의 다른 글
| T-test (T검정) (0) | 2020.09.02 |
|---|---|
| 상관 분석 (0) | 2020.09.02 |
| 외부 파일 읽어오기 - 2 (Excel, JSON) (0) | 2020.05.29 |
| 외부 파일 읽어오기- 1 (CSV) (0) | 2020.05.29 |
| 데이터프레임(Data Frame) 연산 (0) | 2020.05.29 |