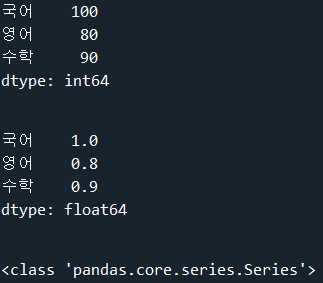
이번 글에서는 konlpy의 Okt tagger를 이용하여 형태소를 추출해보겠습니다. konlpy를 사용하기 위해서는 별도의 설치 과정이 필요합니다. 설치 과정은 konlpy 공식 문서(https://konlpy-ko.readthedocs.io/ko/v0.4.3/install/)에 자세히 나와있습니다. konlpy를 사용하기 위해서는 분석에 사용될 데이터가 필요합니다. 경북대학교 컴퓨터학부 공지사항의 제목 데이터를 스크래핑하여 분석에 사용하겠습니다. # 경북대학교 컴퓨터학부 공지사항 제목 스크래핑 import requests from bs4 import BeautifulSoup if __name__ == "__main__": # requests는 특정 URL로부터 HTML 문서를 가져오는 작업을 수행합니..